Every trial is different. Now the software can be too

AI assistants, bring-your-own code, and a faster way to build decision-grade software
Earlier this year, a pharma partner came to us with a challenging early-phase adaptive trial.
It was not the kind of design that fits neatly into an off-the-shelf tool. The trial included multiple dose levels, dose escalation, interim decisions balancing several efficacy and safety endpoints, and a dose-selection process specific enough that no existing platform could fully capture it.
They needed a simulation and optimization tool built around their design, not a simplified version forced into generic software.
So we built one.
The problem with “almost fits”
In clinical development, “almost fits” is not good enough.
Trial designs are shaped by the science: the endpoints being measured, the way efficacy and safety are balanced, the rules for dose escalation, and the logic for deciding which dose moves forward. Those decisions are often highly specific to a single study.
That is especially true in early-phase adaptive trials, where the design itself is often part of the strategy. Small changes in dose-selection logic or optimization criteria can materially affect the conclusions.
For this partner, that meant they needed more than a simulation tool. They needed a platform that could represent the exact trial they wanted to run, simulate it thousands of times, and help them understand how different design choices would perform under different clinical scenarios.
What we built
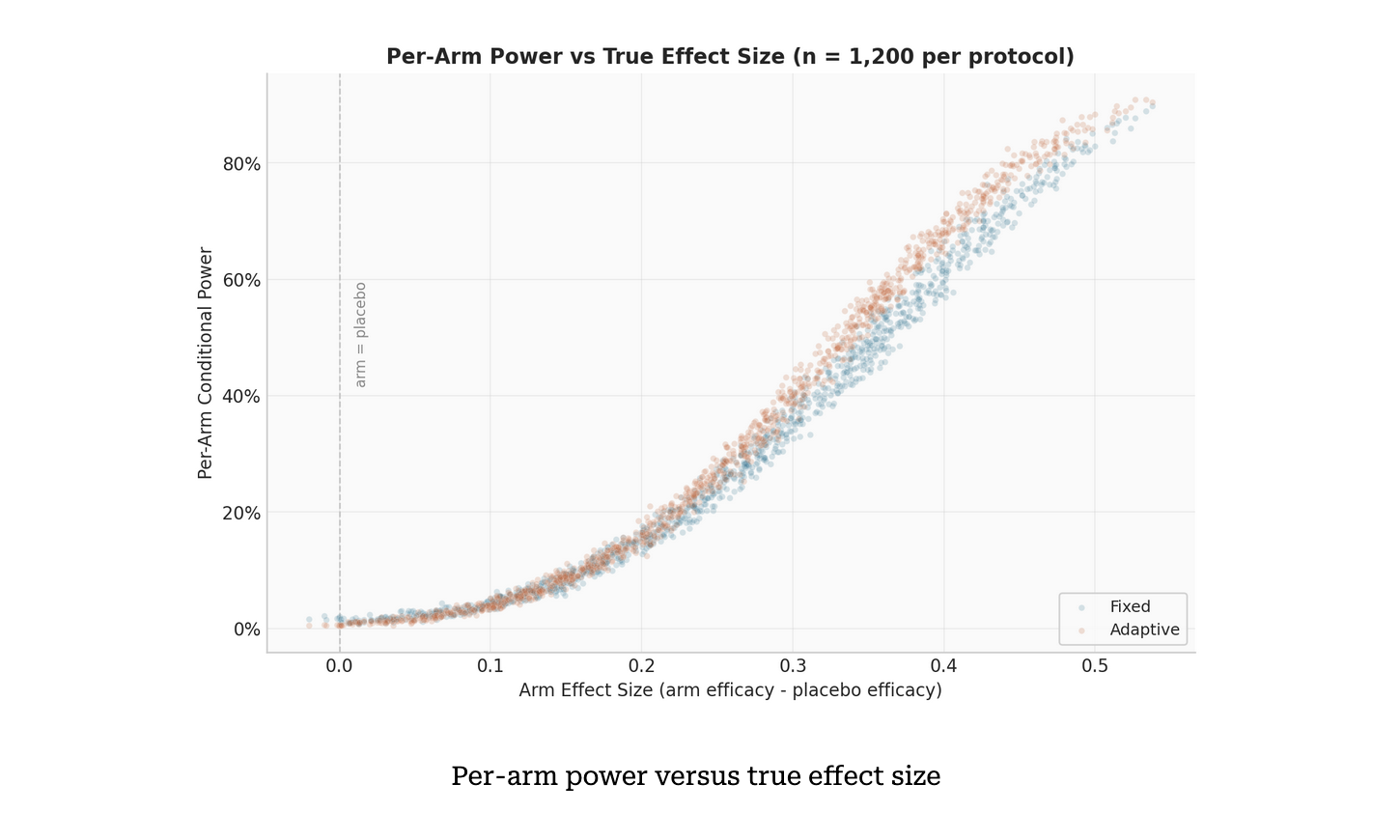
We developed a platform that simulates the full trial thousands of times using Monte Carlo methods, across user-defined clinical scenarios, to estimate how candidate designs perform.
The system supports:
1. full-trial simulation at scale
2. multi-parameter optimization
3. Bayesian dose-selection methods
4. scenario-weighted analysis across different assumptions
But two capabilities stand out.
1. Bring Your Own Code
At the heart of many adaptive trial designs is a deceptively simple question:
Given what we have observed so far, which dose should move forward?
In practice, the answer is rarely simple. Dose-selection logic is often where clinical judgment lives. It may depend on multiple endpoints, thresholds, tradeoffs, and exceptions that are unique to a particular study.
Instead of hardcoding those , we built a safe, Python-like language that lets trial designers write their own decision logic directly in the platform.
That means users can define custom rules for dose selection, validate them instantly, and run them across every simulated trial.
The designer controls the scientific logic. The software handles the scale.
That matters because software vendors should not be the bottleneck for expressing trial-specific decision rules.
What makes this genuinely hard is that the user's logic is defined after the platform is built — effectively at runtime. That creates three competing constraints. The execution environment has to be safe: we cannot allow arbitrary code to run inside our infrastructure. The interface has to be accessible: trial designers are not software engineers, so the language needs to feel like Python without requiring a Python background. And the execution has to be fast: because dose-selection logic runs across thousands of simulated trials during optimization, any performance penalty compounds quickly. Satisfying all three at once — sandboxed, user-friendly, and vectorized for post-processing — is the core engineering challenge behind BYOC.
2. An AI assistant for custom code
Of course, not every trial designer wants to write code.
So we embedded an AI assistant into the platform — one that understands the trial context, including the available endpoints, variables, and supported syntax.
A user can describe the desired behavior in plain language, such as:
“Select the dose with the best efficacy, but only if its safety rate is below 30%.”
The assistant then proposes working code, grounded in the actual structure of the trial design. It can also explain existing logic, help debug it, and refine it iteratively.
The result is a much more accessible workflow: trial designers can express exactly the rules they have in mind, regardless of programming background.
Why this is hard
Every clinical trial is different.
Endpoints differ. Decision rules differ. Dose-selection methods differ. The way a sponsor wants to compare tradeoffs across scenarios differs. That means every engagement requires some amount of custom software.
But the timelines are unforgiving. From initial contact to needing a working tool is often a matter of weeks, not months.
At the same time, the quality bar is extremely high. These tools are not internal dashboards or prototypes. They inform real decisions about whether a drug moves forward. That demands rigor, traceability, and confidence in the results.
So the real engineering challenge is not just building custom software.
It is building custom software quickly, reliably, and at the level of rigor clinical decisions require.
How we made it possible
The speed of this project was not the result of cutting corners. It was the result of having the right foundation and the right process.
A reusable foundation
Over the past several years, PhaseV has built a shared set of components that we can reuse across custom engagements:
1. a simulation engine
2. an optimization framework
3. infrastructure for multi-step configuration flows
4. a common language for describing scenarios and trial designs
A useful analogy is a well-equipped lab with validated instruments. You still design each experiment from scratch, but you are not rebuilding the equipment every time.
That changes the economics of custom software. Each new project starts from tested building blocks, and the team can focus its attention on what is truly unique to the study.
AI-assisted development
Our engineers use AI tools throughout the development process — not only for writing code, but also for drafting specifications, generating and running tests, debugging, and managing changes between versions.
This compresses work that would traditionally take weeks into days.
But there is an important caveat: writing software faster only matters if you can verify it just as fast.
Tight feedback cycles
That is why fast iteration was critical.
Every change our engineers made was automatically tested and turned into a working version of the tool, often within minutes. Suggestions from the clinical team could become testable updates almost immediately.
That rapid loop between idea, implementation, and verification is what made the pace sustainable.
Critically, the client was part of that loop. Each release went back to the partner, who reviewed whether the platform accurately captured their intended trial design and returned new feature requests for the next cycle. Without that loop, speed would be a liability — you would simply ship mistakes faster. With it, fast development becomes genuinely useful. Moving fast only makes sense if you are building the right thing.
What the team delivered
Over three and a half months, a team of five — two engineers and three algorithm specialists — delivered four major releases.
The platform evolved from an initial working simulation into a much more powerful system with:
1. custom user-defined decision logic
2. an embedded AI assistant for writing and refining that logic
3. Bayesian dose-selection methods
4. configurable optimization across clinical scenarios
Four major releases within weeks is a fast pace by any standard. In the context of custom trial design software, it is only possible with the right combination of reusable infrastructure, AI-assisted engineering, and extremely short feedback cycles.
The frequent releases also served a second purpose: they helped the client fine-tune their trial. Clinical trial design is hard, involving many competing goals, operational constraints, and tradeoffs that are difficult to reason about in the abstract. Each release revealed more about how the design performs under simulation, helping the team identify parts that needed more work. The software development and the trial design were happening in parallel, each one informing the other.
The bigger takeaway
This project reflects something broader about how we think at PhaseV.
Clinical trial design is not static. The most valuable work often happens where standard tools run out — where the scientific question is too specific, the decision logic too nuanced, or the design too novel to fit into a prebuilt template.
That is exactly where custom software matters most.
The challenge is doing it fast enough to match clinical timelines, while maintaining the rigor required for high-stakes decisions.
This is the model we are building toward: software that is custom where it needs to be, reusable where it can be, and accelerated by AI without sacrificing reliability.
Because in trial design, moving fast only matters if you can still trust every decision the software helps you make.