We simulated 60 million trials. Here's what we found.

When one number isn't enough to plan a trial
You're meeting to design a Phase 2 dose-finding trial with placebo and three doses. Your biostatistician pulls up the power calculation: pick an expected effect size for each dose, plug it in, get a sample size. So far, so standard.
But which effect size do you pick? Your high dose might improve remission by 20% over placebo, or it might be closer to 40%. Your low dose might barely beat placebo at all. Everyone at the table has a different estimate, and the power calculation only takes one.
That's the problem. Power tells you "if the world looks exactly like this, here's your chance of success." But you don't know what the world looks like. Pick optimistically and you'll undersize the trial. Pick conservatively and you'll oversize it. Either way, you're planning around a guess.
So how do you design a trial when you're uncertain about the very thing you're trying to measure?
Assurance: A more powerful calculation for trial design
When PhaseV simulated possible trial designs using its Trial Optimizer platform, we found a design that required ~5% fewer patients while delivering ~8 percentage points more assurance of success than a conventional fixed design.
The key word there is assurance, not power. Assurance is different from power: it averages the probability of trial success across the full distribution of plausible treatment effects, not a single fixed number. If you’re unsure if your drug’s effect size is 15% or 35%, assurance reflects that uncertainty honestly.
PhaseV Trial Optimizer platform: fixing ambiguity
To optimize this trial, we simulated fixed vs adaptive trial protocols head-to-head. In a fixed design, patients are split evenly between arms, which all run to completion. An adaptive design incorporates interim futility checks, with participants from underperforming arms reallocated to surviving arms.
To estimate assurance, we ran a two-level Monte Carlo simulation, with each trial simulating 250 patients. First, 400 sets of treatment efficacies were drawn from prior distributions, each representing a plausible version of reality. For each set, we simulated 1,000 complete trials under both protocols, giving 400,000 paired simulations per design. A sensitivity analysis incorporated five futility thresholds, five interim schedules and three sample sizes to create 75 design configurations, each evaluated for both protocols. That’s 60 million simulations, so all bases are covered. Simulations of that scale that would take days on a single machine were done at PhaseV in approximately 6 hours.
Adapting a traditional trial design: when the numbers speak for themselves
The results were unambiguous.
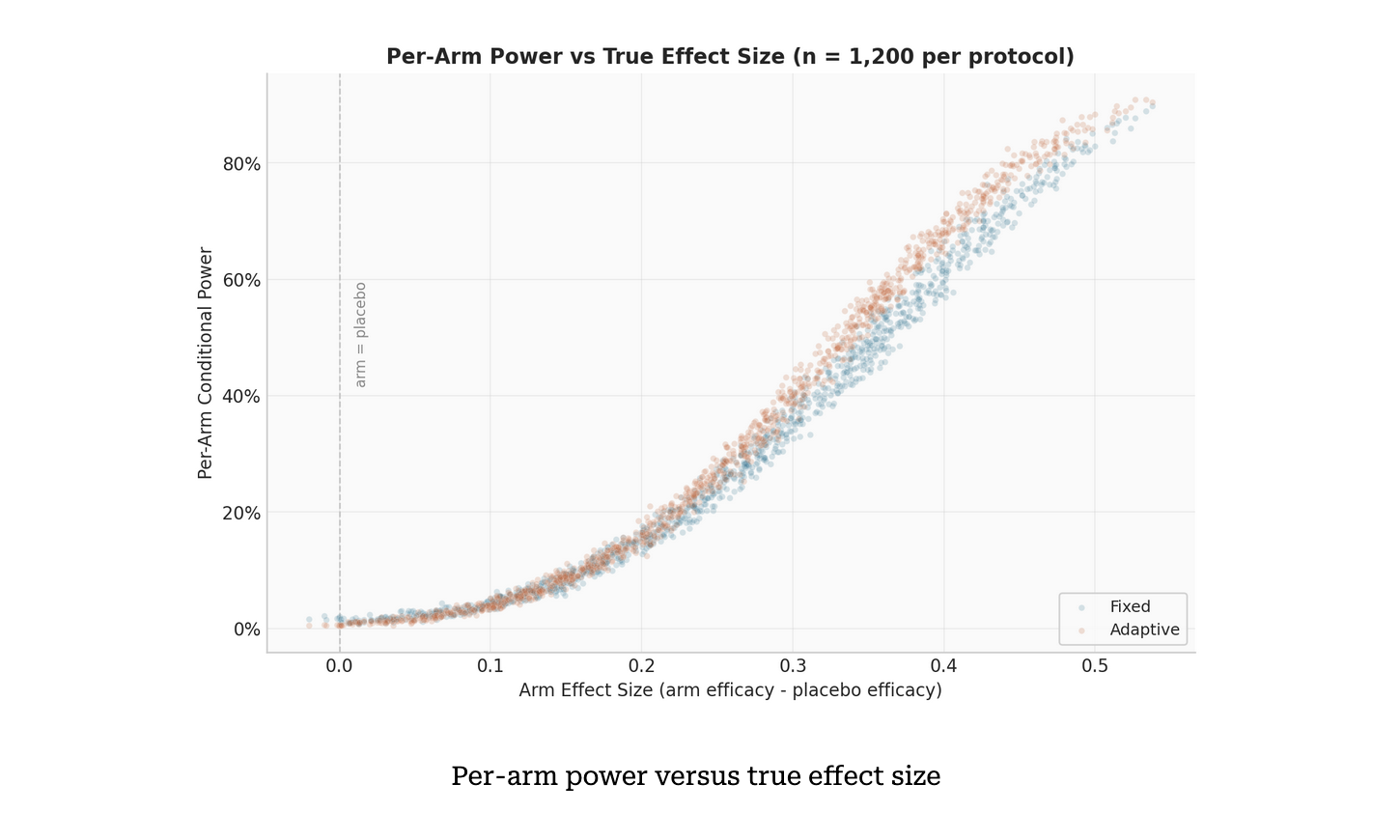
The adaptive design achieved 71.1% assurance of success versus 63.4% for the fixed design - a gain of 7.7 percentage points - while enrolling 5% fewer patients on average. Under the null hypothesis, the adaptive design also stopped the majority of null trials early, substantially reducing unnecessary enrollment. Both designs kept the false positive rate well below 5%. The entire assurance advantage came from better detection of genuinely effective treatments, not from inflated false positives.
In our simulation, when a weak arm's remission rate falls below placebo plus 0.06, it is dropped and patients reallocated to surviving arms increase its effective sample size. Power concentrates exactly where it matters. The Bonferroni correction still divides alpha by three (the original number of active arms), so there’s no statistical trick.
Strikingly, when we compared the two protocols on the same 400 efficacy draws, the adaptive design outperformed the fixed design in almost all cases. The gap ranged from a few percentage points in the highest-power scenarios to over 20 points in moderate-power ones, exactly where reallocation delivers the most benefit.
That advantage proved robust. Across most of the 75 sensitivity configurations, the adaptive design maintained its edge. At moderate futility thresholds (delta = 0.02 to 0.05), the advantage was consistent across interim schedules. Only the most aggressive thresholds (delta = 0.08 to 0.10) at large sample sizes hurt performance, where precise interim estimates led to predictable but incorrect arm dropping. Even then, the effect was marginal.
What 60 Million simulations taught us about trial design
Three things stand out from this analysis.
In a multi-arm trial, not all arms deserve equal investment. An adaptive design that can shift resources away from losing arms toward promising ones mid-trial doesn’t just protect patients from ineffective treatments. It actively sharpens the trial’s ability to detect what works.
Scale of simulation matters. One power calculation at one assumed effect size isn't a full plan; it's optimism, as hopeful as the patients are when they enter your trial. And running both designs across hundreds of plausible scenarios, thousands of trials each on identical simulated patients is how you make real predictions.
Adaptive designs aren’t new. Quantifying their advantage at this level of rigor - 60 million simulations, 75 configurations, full sensitivity analysis completed in hours - is. That’s the kind of evidence that turns a design discussion into a decision.
A smarter way to design trials
Adaptive trials are not new, but what’s changing is our ability to quantify their value with precision. By combining rigorous statistical frameworks with large-scale simulation, we can now make more informed decisions before a single patient is enrolled.
In an industry where every trial counts, that’s a powerful advantage.
And as this analysis shows, when you let trials learn and adapt, the results speak for themselves.